Tutorial
This tutorial page goes through the process to register and submission. It then gives a tutorial on how to set up the baseline of each subtask.
If you have further questions, we encourage you to refer to the FAQ page and use our forum for discussion.
1. Registration
To register for this competition, head to the Participate page and follow the instructions. Please read through the competition rules before you accept to abide by them. After completing and submitting the form, your team will receive an email in the “team” email address provided in the first page of the registration form. Confirm the contents of your submission by double-checking the table attached in the email. If the contents are incorrect, you may edit the response of your registration following a link provided in the email. The “Team Name” field is the text used to identify your submission and publish to the leaderboards.
2. Submission
After your registration, within two work days (PST), you will receive an email with instructions for the submission protocol and a link to a cloud storage folder accessible only by the organizers and your team. You will upload your scripts to this folder and they will be evaluated every Wednesday and Friday throughout the competition, please see our Submission Page for detailed instructions.
3a. Subtask-1 (NER) Baseline Tutorial
 Overview of how our baseline model generates predictions for subtask 1.
Overview of how our baseline model generates predictions for subtask 1.
Subtask-1 (NER) Baseline Tutorial
This pretrained baseline transformer model is adapted from a popular NER competition that leverages the XLM-RoBERTa-base model.
Setting up the code environment
Clone the repo from git
Run the following command to clone the repository containing the scripts to create the baseline model. The relevant scripts will be in the directory ./baseline whereas data for the competition is under the directory ./data.
git clone https://github.com/nl4opt/nl4opt-subtask1-baseline.git
Setting up environment using conda
Create a conda environment for the NER task and install the required packages:
conda create --name nl4opt-ner python=3.9.12
conda activate nl4opt-ner
cd nl4opt-subtask1-baseline/ner_task/baseline
pip install -r requirements.txt
Overview for Running the code for the NL4Opt Baseline
This code repository provides you with baseline approach for Named Entity Recognition (NER). In this repository the following functionalities are provided:
- CoNLL data readers
- Usage of any HuggingFace pre-trained transformer models
- Training and Testing through Pytorch-Lightning
Please see below for a more detailed description on how to use this code is provided.
Arguments:
The arguments are as follows:
--trainpoints to the path of the training data. In the case of the baseline model, this would be ../data/train/train.txt--devpoints to the path of the training data. In the case of the baseline model, this would be ../data/dev/dev.txt--out_dirpoints to the path to save the output files.--iob_taggingcan be adjusted if the tagging scheme is altered. However, this must be converted back to the ‘conll’ tagging scheme prior to evaluation.--max_instancesis the maximum number of instances - we recommend to keep this untouched.--max_lengthis the maximum number of tokens per instance - we recommend to keep this untouched.--encoder_modelis the pretrained encoder to select. The baseline model was trained on xlm-roberta-base but there are many others to choose from.--modelis the path to the model. This is used for fine-tuning and evaluation.--model_nameis name to save your model under.--stageis the stage of training. Either ‘fit’, ‘validate’, ‘test’, or ‘predict’.--prefixis the prefix for storing evaluation files.--batch_sizeis the number of samples in a batch.--epochsis the number of epochs to train for.--lris the learning rate.--dropoutis the dropout rate used.--gpusis the number of gpus to use.--cudais the cuda device.--epochsis the number of epochs to train for.--accum_grad_batchesis the number of batches before accumlating gradients.
p.add_argument('--train', type=str, help='Path to the train data.', default=None)
p.add_argument('--dev', type=str, help='Path to the dev data.', default=None)
p.add_argument('--out_dir', type=str, help='Output directory.', default='.')
p.add_argument('--iob_tagging', type=str, help='IOB tagging scheme', default='conll')
p.add_argument('--max_instances', type=int, help='Maximum number of instances', default=1500)
p.add_argument('--max_length', type=int, help='Maximum number of tokens per instance.', default=200)
p.add_argument('--encoder_model', type=str, help='Pretrained encoder model to use', default='xlm-roberta-large')
p.add_argument('--model', type=str, help='Model path.', default=None)
p.add_argument('--model_name', type=str, help='Model name.', default=None)
p.add_argument('--stage', type=str, help='Training stage', default='fit')
p.add_argument('--prefix', type=str, help='Prefix for storing evaluation files.', default='test')
p.add_argument('--batch_size', type=int, help='Batch size.', default=64)
p.add_argument('--accum_grad_batches', type=int, help='Number of batches for accumulating gradients.', default=1)
p.add_argument('--gpus', type=int, help='Number of GPUs.', default=1)
p.add_argument('--cuda', type=str, help='Cuda Device', default='cuda:0')
p.add_argument('--epochs', type=int, help='Number of epochs for training.', default=5)
p.add_argument('--lr', type=float, help='Learning rate', default=1e-5)
p.add_argument('--dropout', type=float, help='Dropout rate', default=0.1)
Train and evaluate the model
Execute the following commands to train, fine-tune, and evaluate the model on the development set. Participants will not have access to the test set that is used for model evaluation and leaderboard updates.
There are many approaches to training a neural network. However, the baseline framework provided does this in a two-step approach: first with a training session where the model is trained with early stopping; second with a fine-tuning session (potentially with a lower LR, or adaptive LR etc).
Training the model
python train_model.py --train ../data/train/train.txt --dev ../data/dev/dev.txt --out_dir ./trained_model --model_name xlmr_lr_0.0001 --gpus 1 --epochs 25 --encoder_model xlm-roberta-base --batch_size 16 --lr 0.0001
Fine-tuning the model
python fine_tune.py --train ../data/train/train.txt --dev ../data/dev/dev.txt --out_dir ./trained_model --model_name xlmr_lr_0.0001 --gpus 1 --epochs 30 --encoder_model xlm-roberta-base --batch_size 16 --lr 0.0001 --model ./trained_model/xlmr_lr_0.0001/lightning_logs/version_0
Evaluating the model on the dev set
python evaluate.py --test ../data/dev/dev.txt --out_dir ./trained_model --model_name xlmr_lr_0.0001 --gpus 1 --encoder_model xlm-roberta-base --batch_size 16 --model ./trained_model/xlmr_lr_0.0001/lightning_logs/version_1
Results
When evaluating the baseline on the dev set, you should get a micro-averaged F1 score of 0.899.
The model was evaluated on researved samples from the same domain as those released as part of the “training split” (“Source Domain”). The model was then evaluated on the reserved three new domains containing transportation, production, and science problems (“Target Domain”). Finally, the model was evaluated on the entire test set made up of all reserved sampled described above (“Entire Test Set”). The leaderboard and final standings will only consider the micro-averaged F1 score (right-most column) of the submitted models on the entire test set. The baseline model achieved micro-averaged F1 score of 0.906. This model achieved the following F1 scores:
| CONST DIR |
LIMIT | OBJ DIR |
OBJ NAME |
PARAM | VAR | MICRO AVG |
|
|---|---|---|---|---|---|---|---|
| Source Domain |
0.926 | 0.992 | 0.993 | 0.969 | 0.991 | 0.951 | 0.968 |
| Target Domain |
0.936 | 0.992 | 0.993 | 0.420 | 0.968 | 0.910 | 0.883 |
| Entire Test Set |
0.934 | 0.992 | 0.993 | 0.591 | 0.975 | 0.920 | 0.906* |
* Value that will be reported on the leaderboards page and used for the final evaluation when determining the winners.
3b. Subtask-2 (Generation) Baseline Tutorial
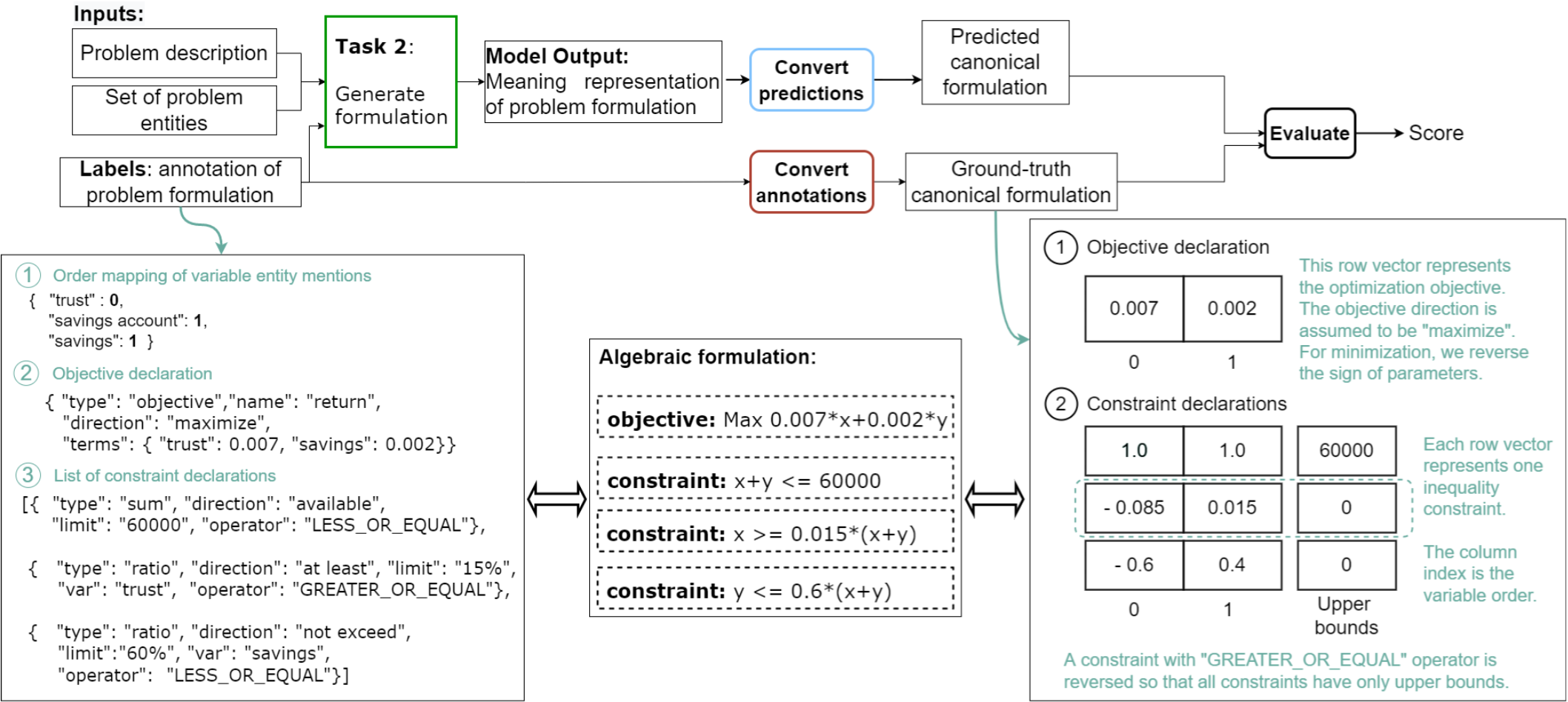 Overview of how our baseline model generates predictions for subtask 2.
Overview of how our baseline model generates predictions for subtask 2.
In the starter kit, you will find the files required to train a baseline model using BART.
Environment Setup
We have provided a Conda environment file environment.yml. To install:
conda env create -f environment.yml
conda activate myenv
Verify that it was installed:
conda env list
Training
The subfolder ./configs should contain the configuration file for setting up the model configuration and the training hyperparameters. The configuration file baseline.json corresponds to the baseline model for subtask 2. To run the training with our configuration:
python train.py --config configs/baseline.json
The important parameters here are use_copy, per_declaration, and use_prompt.
use_copyuses a copy mechanism that computes $P_\text{copy}$ over the input tokens.per_declarationcontrols each training data sample to correspond to a single declaration of a given LP problem instead of the entire formulation (i.e. all declarations in the problem).use_promptuses a declaration prompt to focus the generation. For example, the<OBJ_DIR>is used as a prompt for generating the objective declaration.
Note that beam search is available as an alternative to greedy search in decoding; however, we found that greedy search worked better.
Testing
To evaluate the model:
python test.py --gpu <gpu id> --checkpoint <checkpoint.mdl> --test-file <test.jsonl>
More details about scoring can be found in the notebooks folder here. For reference, our baseline model achieves a per-declaration accuracy of Acc = 0.61 on the test set. Note however that the test set is held out and will not be shared to participants.
For more details, see the README for subtask-2 for a tutorial on training a baseline BART model.